Wiki-Loader: Loading Wikipedia into Neo4J
In April, I put together a Python script that would load an XML export from Wikipedia into a local SQLite database because, once again, you never know when you'll inadvertently become a time traveller who needs knowledge of future events to return home. (Look, it's more interesting than just saying “because I find it amusing”, so just roll with me here.)
This script satisfied the typical time traveler's use-case of “finding a bit of topical information quickly”, yes, but that is only one of the many use-cases that chronological explorers must concern themselves with before traipsing around through spacetime. A seasoned chrononaut would also be aware that they need a way quickly find the relationships between entities and events should they need to topple a series of causal dominos. Just for example, maybe you need a way to get to “Tom Scott” from “Hartselle, Alabama”. 1
Setting Up a Graph Database
While the “R” in RDBMS does stand for relational, little about a standard RDBMS fits our need here: an RDBMS tends to focus more on tabular entities that might have relationships than it does on the relationships themselves. We could awkwardly force the data into an RDBMS for this and still use it, but really a simple graph database more closely reflects the conceptual structure we need and provides a more fitting set of querying capabilities that match our needs. By using a system that fits our mental model, we don't have to devolve into trying to derive relationships from rows in the result set when we query data. 2
So, if not an RDBMS, what will we use? This sounds to be more the domain of graph databases, so we'll use an instance of Neo4J here. Though the most straight-forward path to get it going is probably to use installer, I prefer to use Docker as it makes it easier for me to manage long-term. To spin up a Docker container, we need only copy-paste the following into a file named docker-compose.yml and to run docker-compose up (assuming Docker is installed).
version: '2'
services:
neo4j:
image: neo4j:4.2
environment:
- NEO4J_AUTH=neo4j/ChooseDecentPasswords
- NEO4J_dbms_memory_pagecache_size=1G
- NEO4J_dbms_memory_heap_max__size=4G
- NEO4JLABS_PLUGINS=["apoc","graph-data-science"]
ports:
- 7474:7474
- 7687:7687
volumes:
- ./volumes/data:/data
- ./volumes/logs:/logs
restart: always
For those that aren't familiar with Docker, we're downloading the official Neo4J image, setting the initial login credentials, upping the memory allocation, and installing the apoc and graph-data-science plugins of Neo4J. If you prefer, feel free to just use an installer.
Either way, whether using a product installer or a Docker container, at this point navigating a browser to http://localhost:7474 should reveal the Neo4J browser. After entering the credentials passed above (or set during initial installation), the view should be something like the below.
We'll be coming back to this later on.
The Plan
So this is a good time to go over the basic plan: since we already have a straightforward way to extract content from XML, we can ignore that specific detail, reusing what we have from the last post. Instead, let's just focus on the specifics of extracting links between pages and connecting to Neo4J.
Extracting Links
Within the page text, links to other pages are represented using a format like [[Page Name]] or [[Page Name|Visible Alias]]. Since the pattern itself can be described as “the shortest string appearing between two pairs of square brackets”, this is an ideal candidate for using a regex. Once we've extracted a link, we can split it on the pipe character and simply dispose of the alias.
@staticmethod
def _extract_references(content):
# Look for text matching [[target]] or [[target|display text]]
pattern = re.compile("\\[\\[([^\\]]+)\\]\\]")
return [x.split("|")[0] for x in re.findall(pattern, content_minus_refs)]
Given the above, we now have a quick way to get the links (edges) from our page texts (nodes). 3
Connecting to Neo4J
Since we're using the framework from our previous post, we should be able to get most of the way to our goal by creating a new PageWriter that connects to Neo4J. Running pip install neo4j and adding the below PageWriter boilerplate gets us to the more interesting bits.
from wikipedia import ContentPage, RedirectPage
from neo4j import GraphDatabase
class Neo4jPageWriter:
def __init__(self, uri, user, password):
self.uri = uri
self.user = user
self.password = password
self.connection = None
self._indexed_namespaces = set()
def __enter__(self):
self.connection = GraphDatabase.driver(self.uri, auth=(self.user, self.password))
return self
def __exit__(self, exception_type, exception_value, exception_traceback):
self.connection.close()
def on_page(self, page):
pass
With the boilerplate in place, we can replace our empty on_page implementation with one that will store data in our graph database.
def on_page(self, page):
with self.connection.session() as session:
namespace = type(page)
if namespace is ContentPage:
session.write_transaction(self._write_content_page, page)
elif namespace is RedirectPage:
session.write_transaction(self._write_redirect_page, page)
else:
raise Exception("Could not store page of unknown type")
While it isn't completely different from the way that we run SQL against an RDBMS, there are some key differences that can be seen by analyzing our implementation.
The first difference is that, rather than creating transactions directly from a connection, we have an extra step: connections have sessions and session have transactions. The extra step here is a byproduct of Neo4J's cluster architecture: Neo4J supports having multiple write nodes within a cluster, and allows writes to be handled by any write node, regardless of where previous writes in the same session were routed. In order to provide a consistent view of data, regardless of which node is handling a request, the session object keeps track of what order transactions occurred within the session and uses that information to ensure that the whichever node is handling the request has already processed all transactions from the session and that it has processed them in the correct order. This allows it to present a consistent view of the underlying data.
A second thing to note is that we are passing a static method into Neo4J's write_transaction as a unit-of-work, as opposed to getting a transaction object from it that we then manipulate. While this may seem strange at first, embracing the Unit of Work pattern gives Neo4J a clean way to implement retry logic when necessary (such as if the current write node becomes unavailable) while also encouraging cleaner code and separation between business logic and data access.
Inserting Data
With this in place, the next thing for us is to review the actual process writing to the database.
@staticmethod
def _write_content_page(transaction, page):
target_titles = _extract_references(page.content)
for target_title in target_titles:
transaction.run("""MERGE (source:Page { title: $source_title })
MERGE (target:Page { title: $target_title })
MERGE (source)-[:LINKS_TO]->(target)""",
source_title=page.title, target_title=target_title)
To perform CRUD operations against Neo4J, we need a small bit of Cypher, the query language used by Neo4J. In order to insert our nodes and our relationships, we only need three lines: the first of these lines tells the graph to MERGE, or rather CREATE IF NOT EXISTS, the entity that follows it. Since it is wrapped in parenthesis, that entity is a node. Within the parenthesis, we then have (in this order), the name of the variable that we can later use to reference this entity, a colon, the node label (this can be thought of as the type, which in this case, is Page), and finally an object containing the attribution for the node. The second line is a copy of the first except that it holds the node in a different variable and uses a different placeholder for attribution. Finally, the third line ties it all together by MERGEing a relationships that relates the two previously MERGEd entities. This third line visually looks like an ASCII arrow pointing from the source to the target, where the arrow itself has square brackets that define a relationship label (in this case, the relationship label is LINKS_TO.) This same logic shows up again when creating a redirect, with only the relationship label changing.
@staticmethod
def _write_redirect_page(transaction, page):
transaction.run("""MERGE (source:Page { title: $source_title })
MERGE (target:Page { title: $target_title })
MERGE (source)-[:REDIRECTS_TO]->(target)""",
source_title=page.title, target_title=page.target)
While this will be enough to get going, those MERGE will be slow since they don't have an index to perform lookups against (since it acts similar to a SELECT and INSERT). If we want any acceptable speed, we'll need to go ahead and add an index on Page.title up-front.
def _create_indices(self):
def create_index(transaction):
transaction.run(f"CREATE INDEX Page_title IF NOT EXISTS FOR (x:Page) ON (x.title)")
with self.connection.session() as session:
session.write_transaction(create_index)
With this in place, we can add a call to self._create_indices at the end of __enter__, start the application up and wait while data starts flowing into the database.
Querying Data
While it's nice that data is going into the database, to accomplish any purpose, we need a way to get it back out. If we are to query the data or do any QA later (ominous foreshadowing) we'll need a way to query data back from the graph.
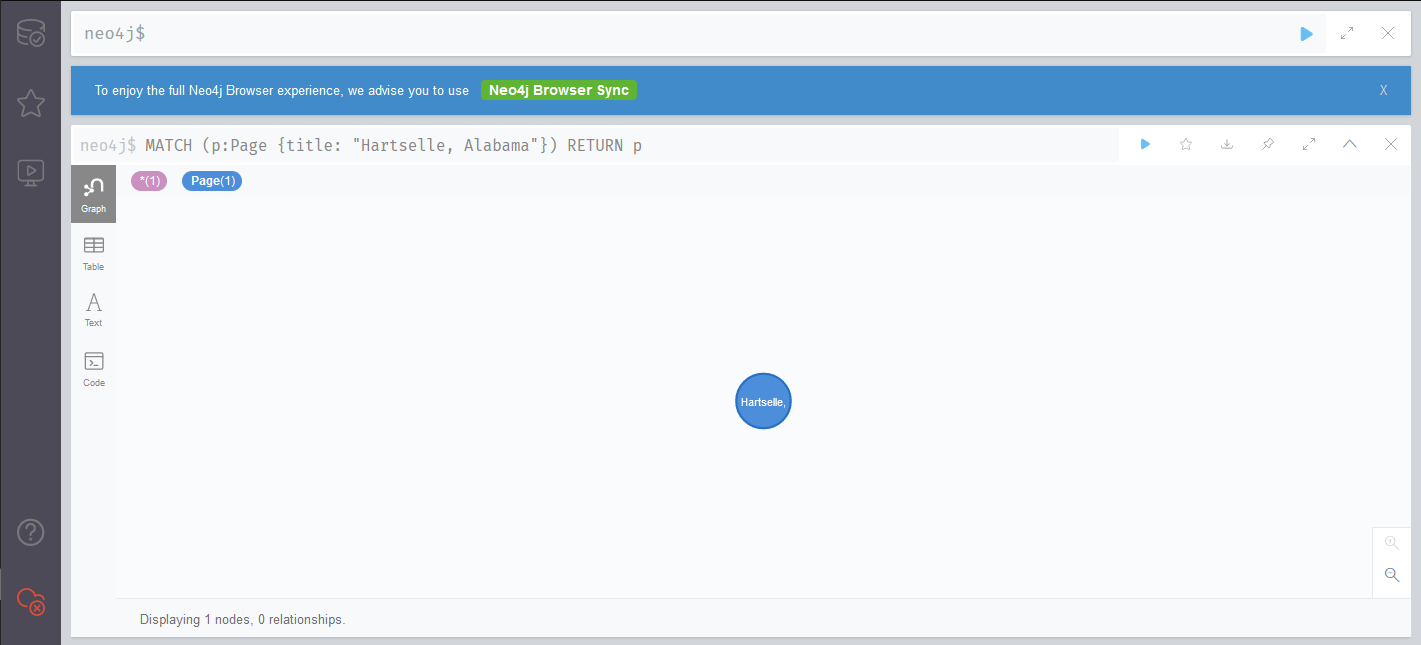
The syntax for querying, or MATCH-ing, is similar to the syntax we used earlier for insertion. If, for instance, I wanted to load the node for “Hartselle, Alabama”, the only real changes from our insertion syntax are that I would use MATCH instead of MERGE and that I would return the result set.
MATCH (p:Page {title: "Hartselle, Alabama"})
RETURN p
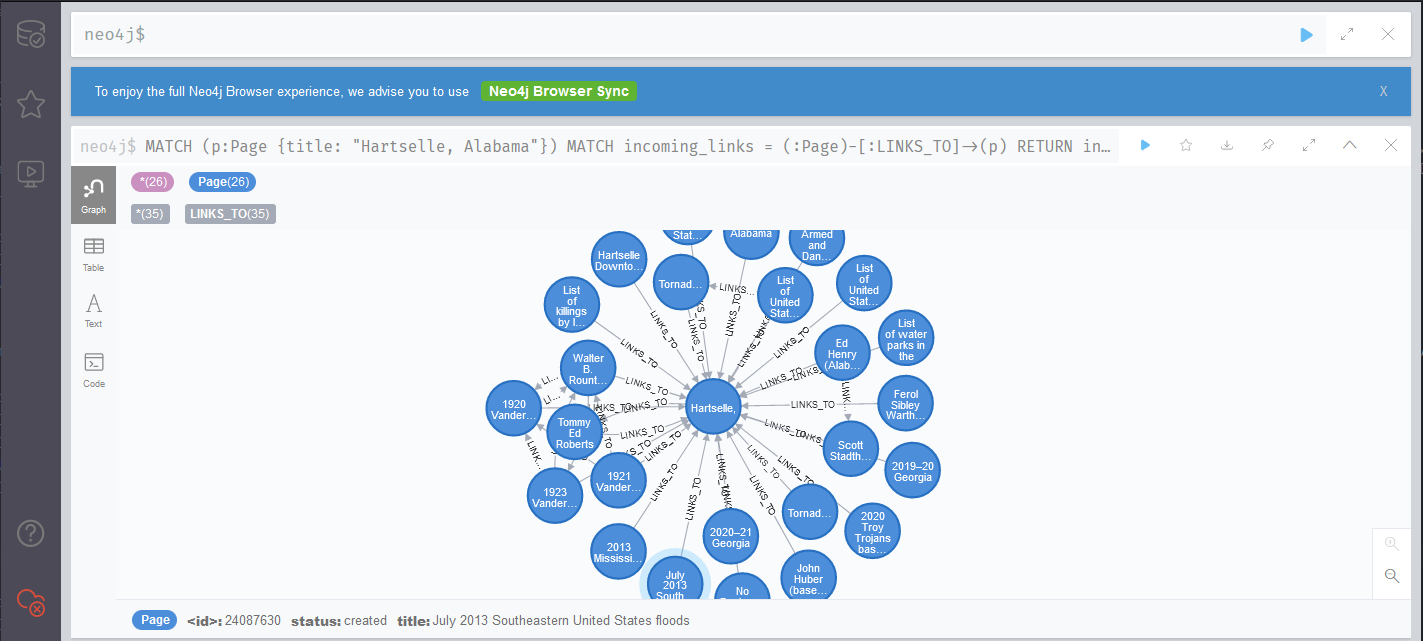
Going a step further, if I wanted to find all of the links to a given page, I could add another MATCH, this time returning all of the relationships themselves
MATCH (p:Page {title: "Hartselle, Alabama"})
MATCH incoming_links = (:Page)-[:LINKS_TO]->(p)
RETURN incoming_links
LIMIT 25
However, the query we'll be using the most is one that finds the shortest path between two nodes using only outbound LINKS_TO relationships. Additionally, I want to cap the number of relationships we can travel through to 5, so that we never end up with a chain longer than 6 nodes from end-to-end.
MATCH (p1:Page {title: "Hartselle, Alabama"})
MATCH (p2:Page {title: "Tom Scott (entertainer)"})
MATCH p = shortestPath((p1)-[:LINKS_TO*1..5]->(p2))
RETURN p
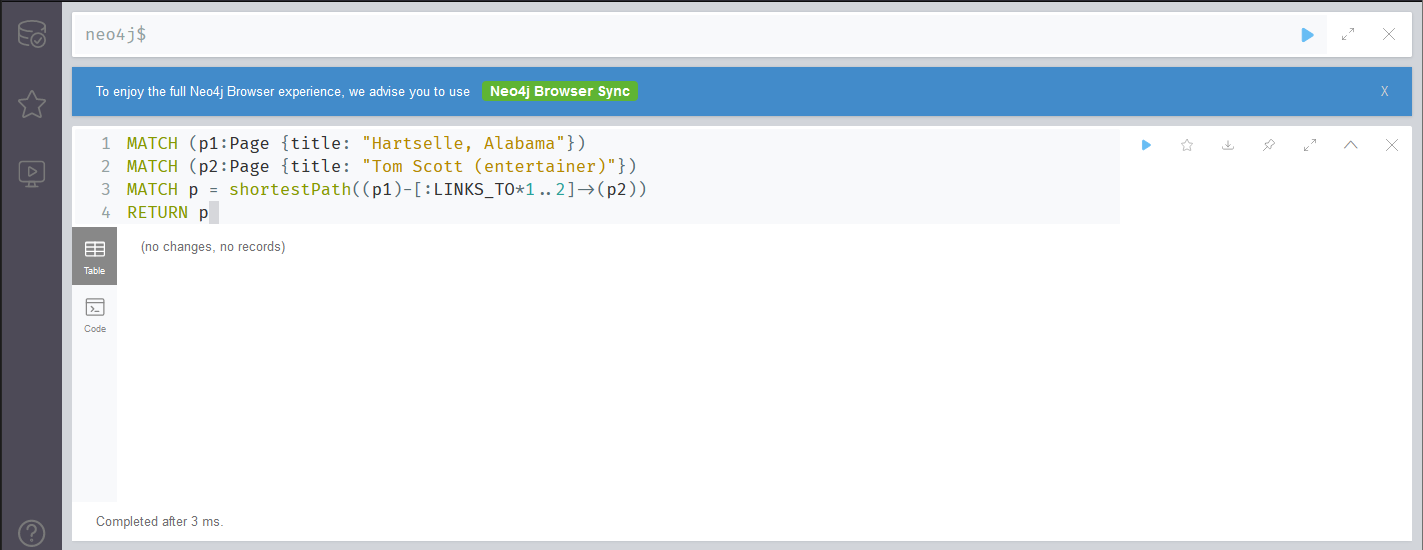
Oh. This one didn't return anything. Given that we've only just started loading our graph though, this makes sense, as there likely is not path yet.
Thankfully, it shouldn't take long so, in theory, we should be able to try again soon.
The Problem With Theories: #1
At least that was the way it was supposed to work. Welcome to the behind the scenes of “things I normally don't include”, because we all know that theory never works right the first time.
After two minutes of loading pages, only a hundred pages had been imported, revealing my first problem: performance. While it technically worked, it was too slow to be practical. Creating relationships with a for loop rather than efficiently using Cypher was allowing us to insert roughly one page per second. Given that there were millions of pages of content along with redirects from renamed pages, “shouldn't take long” would be about 4 1/2 months at the rate it was going.
While leaving a computer running a high CPU task for the full summer was an option, I decided using more efficient Cypher would be a better call than hoping that the power didn't flicker a single time for 1/3 of the year.
@staticmethod
def _write_content_page(transaction, page):
target_titles = _extract_references(page.content)
transaction.run("""MERGE (source:Page { title: $source_title })
FOREACH (target_title in $target_titles |
MERGE (target:Page { title: target_title })
MERGE (source)-[:LINKS_TO]->(target))""",
source_title=page.title, target_titles=target_titles)
After this change, it still isn't as fast as the SQLite ingestion, but it has gone from four months to four days, so I consider this acceptable. At this point, it was ready for a truncate, restart, and then to wait on the data. At least, you know, in theory.
The Problem With Theories: #2
After letting it run for a few hours, I decided to come check on its progress. Overall things were taking shape, albeit slowly, but as I looked around, I started to find a few anomalies. Sure, I had nodes with names like “Altoona, Alabama”, but I also had nodes with names like “File:Sagan planetary orbits2.jpg” and “Category:States of the United States”. Obviously there was something wrong with my parser, right? Well, no… there wasn't. At least not this time. There was plenty wrong with it (spoiler), but in this particular case, it turned out to be working properly: there actually are pages on Wikipedia for both of the aforementioned items. This is when I learned that Wikipedia has namespaces that it uses to categorize entries. There are different namespaces for Files, Categories, Talk, and Users, amongst other things. My mental model of “Wikipedia is pages of encyclopedic content” was obviously wrong, as was the code it had helped form.
So from a brief bit of reading on Wikipedia about namespaces, it appeared that it treats namespaces as the bit before a colon, if one exists, or implicitly in the main namespace (which I opted to name ‘Page’) if none is specified. Unless we wanted to ignore the spirit of our traversal goal and allow for shortest paths to pass through “cheaty” pages, such as “Category:American monster movies", we'd need to update our insertion logic to be aware of namespaces.
Thankfully, extracting the namespace was rather straightforward.
def _parse_title(text):
namespace, title = text.split(":") if ":" in text else ("Page", text)
return { "namespace": namespace, "title": title }
Unfortunately, MERGEing nodes with a variable label was significantly less straightforward. To be more precise, Cypher just doesn't allow it (talk about less straightforward). Thankfully, the apoc plugin provided a number of housekeeping functions, one of which did exactly what I wanted. 4
source_node = _parse_title(source)
target_nodes = [_parse_title(x) for x in targets]
for node in [source_node] + target_nodes:
self._create_index_if_missing(node["namespace"], "title")
transaction.run("""CALL apoc.merge.node(
[$source.namespace],
{title: $source.title}
) YIELD node AS source_node
WITH source_node
UNWIND $targets as target
CALL apoc.merge.node(
[target.namespace],
{title: target.title}
) YIELD node AS target_node
MERGE (source_node)-[:LINKS_TO]->(target_node)""",
source=source_node,
targets=target_nodes)
Now, all that was left was to ensure that any newly created labels had indices. Since the existing approach of generating the index up-front no longer made sense, I removed the call to _create_indices from __enter__ and then replaced the whole method with a slightly more apt _create_index_if_missing.
def _create_index_if_missing(self, label_name, field_name):
def create_index(transaction, name, field):
transaction.run(f"CREATE INDEX {name}_{field} IF NOT EXISTS FOR (x:{name}) ON (x.{field})")
if label_name not in self._indexed_namespaces:
with self.connection.session() as session:
session.write_transaction(create_index, label_name, field_name)
self._indexed_namespaces.add(label_name)
It does get called for every page and link being inserted, but the overhead of checking for an item in a set is sufficiently low, especially given that the set will only ever hold a few dozen entries. I might could have found a more performant approach but it would have been a net waste of time since this likely only contributes two or three minutes to a 4 day process.
It was time again to test the theory.
The Problem With Theories: #3
After another while of importing, things looked significantly better: I was able to see all the links to or from a page, and could traverse relationships without unintentionally running into Talk, or File pages. Everything was fine until I ran into a node named “nachos”. It seemed odd that this one was lowercase while every other I had seen was title case. And, as I had feared, it was odd: I had distinct nodes for both “nachos” and “Nachos”.
After a brief tour through Wikipedia's page naming rules, it turns out that pages are case sensitive, except for the first character, which is always to be treated like it has been upper-cased. So, as long as we simply uppercase the first letter, our logic should be fine again.
def capitalize(s):
return s[0].upper() + s[1:]
I was ready for the next cycle of “truncate, restart, and wait”. Then the results would be in… in theory?
The Problem With Theories: #3b
After leaving it for a solid day to let it process, I came back to find that that the importer had failed with an error:
IndexError: string index out of range
But how was that possible? My guess was that single character page names were tripping up my s[1:], so I updated the code to handle that and did another truncate, restart, wait.
def capitalize(s):
if len(s) <= 1:
return s.upper()
return s[0].upper() + s[1:]
Soon, results would be in. You know, in…
The Problem With Theories: #3c
Another day, another failure, but this time it was the exact same as the one before it.
IndexError: string index out of range
Had I not saved my changes before launching the app? I had.
The problem wasn't that the last code change wasn't saved but rather that it was just plain wrong: s[1:] wouldn't throw an error even with a single character string. That meant s[0] had to be the problem. Certainly there couldn't be a page with a zero length in the dataset? Was someone just messing with me? To no-ones surprise, no, I wasn't the target of some pointless conspiracy but rather I had forgotten about one of the cardinal rules of computer science: never trust user data. In this case, I had been bitten by the rare occurrence of someone leaving a completely stray [[]] in the middle of an otherwise normal article. It seems that that happens from time-to-time, such as seen on the page for Expert. The irony runs deep.
This time it would maybe definitely work. Probably. In theory.
The Problem With Theories: #4 - #8
At this point, roughly five days had passed and the entirety of the data had been loaded. Thankfully, everything looked good… except for the presence of both Billboard_(magazine) and Billboard (magazine)… Sure enough, both of those are referenced in Wikipedia, so both of them got created here.
Okay, no more Mr. Nice Guy: after a bit of searching, it turned out the technical restrictions on naming rules for Wikipedia were significantly more involved than I had thought and there were still a number of cases I wasn't properly handling.
While there is a beautiful irony in living out my own personal Groundhog Day while trying to prep for unintentional time travel, I'd hit my quota on irony. Before going any further I went back and added unit tests for all of the rules that I'd already implemented, finding and fixing some edge cases along the way. With those in place I then went on to add support for more rules that I had only just discovered in the link above:
- Underscores and spaces are functionally equivalent.
- Multiple underscores or spaces are treated as only a single space.
- Pages starting with the
Wnamespace (e.g.W:Lego) are the same as pages with no namespace (e.g.Lego). - In the
Talknamespace, page names extend only to the first forward-slash in the title. In all other spaces, slashes are considered part of the title. - In every namespace, page names extend only to the first
#, if it exists.
With tests for these in place, it was time for another truncate, followed by several days of loading before finally getting the database. At least in theory.
Success, Qualified
After another almost week of “truncate, load, wait”, it looked like the graph was loaded successfully. Despite looking around for a while, I couldn't find anything that appeared out of place this time. Finally, the graph was ready to query. And query I did. I threw masses of queries at it and it threw paths back at me (which I would then manually verify). Though some of them seemed suspicious (Twitter links to Lego, for instance), everything was in fact, accurate.
While exploring various links, however, I found one link that made me reload the entire graph yet again: “The Lego Movie 2: The Second Part” to “Los Angeles Times”. Why this particular link? Let's take a look at how it shows up on the page.
$99 million<ref>{{cite web|url=https://www.latimes.com/entertainment/la-fi-ct-box-office-lego-movie-20190207-story.html|title='Lego Movie’ sequel and ‘What Men Want’ to boost box office after Super Bowl doldrums|website=[[Los Angeles Times]]|…}}</ref>
The only reference to the Los Angeles Times on that page occurred when they were being cited in the references. I found this to be another case of “breaking the spirit of the challenge”, so I truncated the dataset and reloaded it, this time with one final tweak inside _extract_references with the purpose of stripping references:
def _extract_references(content):
# While the <ref></ref> element can definitely contain references, I exclude them here
# since my concept of a reference can be summed up as "a link that I'm likely to see
# while reading the content body of a page"
content_minus_refs = re.sub("<ref>.*?</ref>", "", content)
# Look for text matching [[target]] or [[target|display text]]
pattern = re.compile("\\[\\[([^\\]]+)\\]\\]")
return [x.split("|")[0].split("#")[0] for x in re.findall(pattern, content_minus_refs)]
Success, At Last
After another near week had passed, I had the graph processed again. Unlike previous runs, this one hit the spot; while some of the paths had surprising links between them, those links were actually in the body of the text. Given a diverse a set of topics, I could be sure that any path returned was valid and that if no path was returned, there actually was no path that fit my criteria. 5
MATCH (p1:Page {title: "Rocket City Trash Pandas"})
MATCH (p2:Page {title: "David Bowie"})
MATCH p = shortestPath((p1)-[:LINKS_TO*1..5]->(p2))
RETURN p
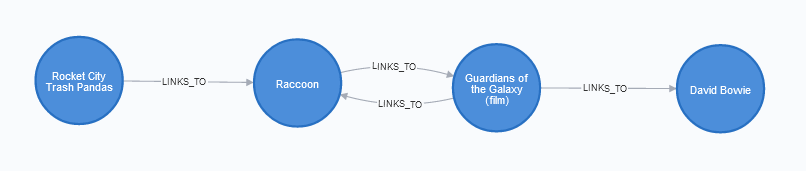
Yes! This is exactly the kind of thing that I was wanting! Let's try it again, but this time looking for the path I found between “Hartselle, Alabama” and “Tom Scott”.
MATCH (p1:Page {title: "Hartselle, Alabama"})
MATCH (p2:Page {title: "Tom Scott (entertainer)"})
MATCH p = shortestPath((p1)-[:LINKS_TO*1..5]->(p2))
RETURN p

Well, it seems that Neo4J found a shorter path than the one I had devised, so I think we can call this a success. (Sorry Steve and Matt.)
For the interested, the final code from this post can be seen here. (There are some minor difference, but none of them are substantial.)
Footnotes
(To note, my preferred path from “Hartselle, Alabama” to “Tom Scott” is the more round about “Hartselle, Alabama” to “Destin Sandlin” to “Steve Mould” to “Matt Parker", and finally to “Tom Scott". Not only is this a reasonably short path from Hartselle to Tom Scott, but it makes for excellent edu-tainment to boot.) ↩︎
This is one of those things that seems surprisingly controversial: a tabular world view is not always appropriate, depending on the task. When talking about non-RDBMS solutions to problems, I invariably get at least some resistance based on the idea that “an RDBMS can do if you just implement the necessary stored procedures or use a vendor add-on.” While that is generally true, shoehorning data into a impractical structure simply because it can be transformed from that representation when needed doesn't make sense as there are countless impractical representations that could be used, all of which are less practical (by definition) than an appropriate representation. ↩︎
Two notes here: First, I opted to split the page id and alias using a basic
.split("|")rather than a regex, since I personally find that easier to read. A regex would have undoubtedly worked, but I generally try to save them for occasions where their level of information density can still be considered the most readable option. There is a reason, after all, that regexes are included in the humorous listing of write-only languages. Second, the astute reader might have noticed an extra[^\\]]+wedged in the middle of the regex, rather than a.+. You're probably wondering why that is there. So am I. I wrote this code four months ago and that is the one thing that I didn't leave a comment on. See the previous comment about why I tend to beware uninhibited use of regexes. ↩︎It also gave me a chance to learn about
UNWIND, which basically creates a cartesian product of source * targets. The alternative, as I understand it, would have been to waste time by returning all of the node ids that had been created and then to use aFOREACHs to retrieve them again. ↩︎There is no guarantee that a path exists between any two nodes in the graph, much to the potential disappointment of many Kevin Bacon theorists. As a trivial example, there are pages, such as the page for Australia's Surfing Life magazine which has content but no outbound links. ↩︎