Wiki-Loader: Loading Wikipedia into SQLite
The code for this post can be found on my GitLab
While the last two years have realized a number of risks that we had all left unmitigated for far too long, one even greater risk has yet to be realized: the risk of unscheduled time travel. Yes, the grave concern that must be considered is that one moment you might be hanging out in the mall parking lot and the next you might find yourself delicately navigating 1955, aware that your only hope for return is tied to some esoteric piece of knowledge such as “when will the clock tower be struck by lightning”? Though I haven't looked up the exact per-capita statistics of this happening, my gut tells me that we would do well to have a plan in place to mitigate this risk. This is, after all, a very serious danger. Very serious.
But, how does one even start managing risk here? How can we be sure we'll have whatever minutia of information that will be needed should we find ourself chronologically displaced? The most straight-forward approach I see is to spend every night and weekend cramming all known pieces of information into my cranium. However, I think I might be better off if I take a less brute-force approach. Rather than become a literal know-it-all, I could keep my own Grey's-Sports-Almanac-esque cheat-sheet with me at all times. It would be more comprehensive, more reliable, and absolutely wouldn't backfire catastrophically.
Downloading Wikipedia
Given the sound reasoning of bringing future knowledge into the past, the next step here would be to figure out how to achieve such a plan. Given that the latest World Book Encyclopedia is a not-so-portable 14,000 pages of print, we might be better served by using something a bit more digital, such as an offline copy of Wikipedia, if one were available. And, as fortune would have it, the Wikimedia Foundation makes compressed XML exports of all articles available near weekly. Weighing in at 6.1 million articles and accessible offline from any reluctant time-traveler's laptop, this is likely to be the closest thing that we might find to an ideal solution.
To start, let's download the archive from the location below.
wget https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles-multistream.xml.bz2
Examining the Format
After some 70+ minutes of downloading a compressed XML over a throttled connection, we're finally ready to start some basic processing. As a first step, we'll need to start by getting an understanding of the data format. Since we can assume it to be a relatively simple dataset, albeit quite large, we can just take a sampling of the document to get an idea of the structure. Let's start by viewing the first eight kilobytes to see if we piece together an understanding.
bzcat enwiki-latest-pages-articles-multistream.xml.bz2 | head -c 8192
<mediawiki xmlns=“http://www.mediawiki.org/xml/export-0.10/“ xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance” xsi:schemaLocation=“http://www.mediawiki.org/xml/export-0.10/ http://www.mediawiki.org/xml/export-0.10.xsd” version=“0.10” xml:lang=“en”>
<siteinfo>
<sitename>Wikipedia</sitename>
<dbname>enwiki</dbname>
<base>https://en.wikipedia.org/wiki/Main_Page</base>
<generator>MediaWiki 1.36.0-wmf.14</generator>
<case>first-letter</case>
<namespaces>
<namespace key=“-2” case=“first-letter”>Media</namespace>
<namespace key=“-1” case=“first-letter”>Special</namespace>
<namespace key=“0” case=“first-letter” />
...
</namespaces>
</siteinfo>
<page>
<title>AccessibleComputing</title>
<ns>0</ns>
<id>10</id>
<redirect title=“Computer accessibility” />
<revision>
<id>854851586</id>
<parentid>834079434</parentid>
<timestamp>2018-08-14T06:47:24Z</timestamp>
<contributor>
<username>Godsy</username>
<id>23257138</id>
</contributor>
<comment>remove from category for seeking instructions on rcats</comment>
<model>wikitext</model>
<format>text/x-wiki</format>
<text bytes=“94” xml:space=“preserve”>#REDIRECT [[Computer accessibility]]
{{R from move}}
{{R from CamelCase}}
{{R unprintworthy}}</text>
<sha1>42l0cvblwtb4nnupxm6wo000d27t6kf</sha1>
</revision>
</page>
This appears to be straightforward enough: the top-level mediawiki element contains a siteinfo element that contains some basic data, such as listing namespaces. After this the mediawiki element continues with one page element for each page on the site. Each page element has a title, namespace (ns), id, text, and potentially a redirect. If there is as redirect, the text can be ignored since it only provides the markup for the redirect itself.
Parsing the XML
Parsing this XML file shouldn't be too much of a problem. We'll just throw it through ElementTree and we'll almost be done parsing.
import bz2
import xml.etree.ElementTree as ElementTree
with bz2.open('enwiki-latest-pages-articles-multistream.xml.bz2') as file:
tree = ElementTree.parse(file)
pages = tree.getroot().findall('./page')
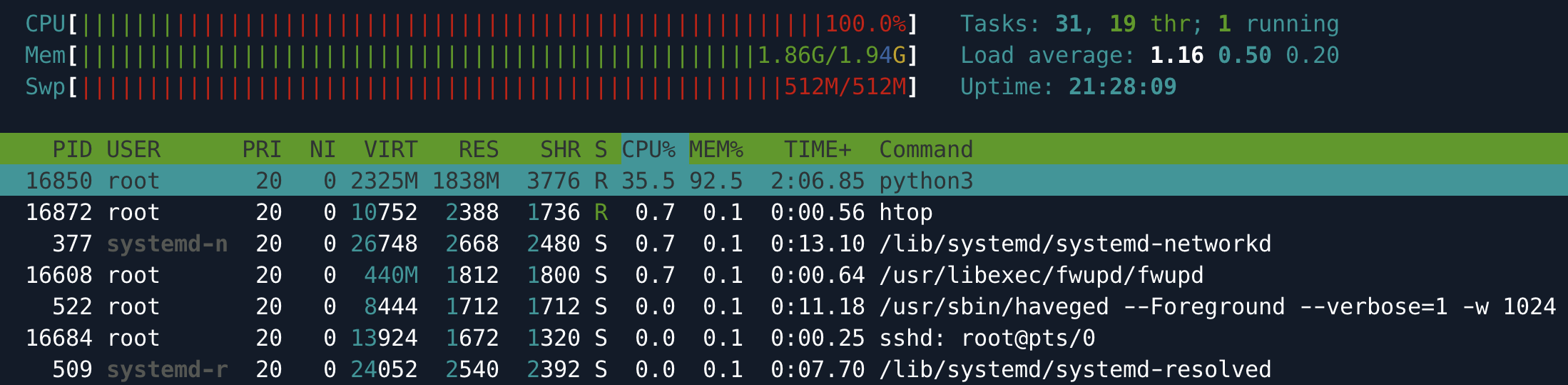
…And, if you tried this, you know that it is a sure recipe for failure. Eager parsing requires that you have enough RAM to back the objects in memory. Given that we are parsing a 78Gb XML stream on a VM with only 2Gb of RAM, this doesn't bode well.
We need to rethink our approach entirely. Rather than eager parsing, let's move to a lazy approach, such as the one provided by SAX. SAX is an event-based XML parsing API that, rather than providing us with the final state of the document, will notify callbacks every time a tag is parsed. This change, notifying us of each primitive parsed, means that very little has to stay in memory at any one point. In fact, the actual memory requirement is roughly constant regardless of the volume of XML to be parsed, making it one of the few reasonable approaches for parsing this.
Still, this trade-off is just that: a trade-off. By optimizing to use less memory, we're accepting increased code complexity and accepting that we must take a direct role in the parsing logic. Still, this trade-off is necessary and won't come at too high of a cost since the process itself is rather simple conceptually. Since SAX notifies us at the start and end of elements, and when a body is ready, we have all the information we need to generate our objects.
Conceptually our strategy is going to look alot like a depth-first tree traversal. For this, we'll treat the document as a stack. Every time we see a start element, we'll create a new object, place it on the stack, and attach it to the object that was previously on the top of the stack. When we see an end element, we'll pop the top element. When the last object is popped off of our stack, we'll send it to a callback.
import xml.sax
class LazyObjectHandler(xml.sax.ContentHandler):
def __init__(self, callback):
self.callback = callback
self.breadcrumb = [{}]
self.skipped_first_node = False
self.content = None
def startElement(self, name, attrs):
if not self.skipped_first_node:
self.skipped_first_node = True
return
tag = {"name": name, "attrs": attrs, "content": ""}
self.breadcrumb[-1][name] = tag
self.breadcrumb.append(tag)
self.content = []
def endElement(self, name):
self.breadcrumb[-1]["content"] = "".join(self.content)
self.breadcrumb.pop()
if len(self.breadcrumb) == 1:
self.callback(self.breadcrumb[-1][name])
self.breadcrumb = [{}]
def characters(self, content):
if content is None or len(content) == 0 or self.content is None:
return
self.content.append(content)
def load_xml(file, callback):
parser = xml.sax.make_parser()
parser.setContentHandler(LazyObjectHandler(callback))
parser.parse(file)
Objects created with this strategy are essentially nested dictionaries with the same layout as the input element with the addition of three extra synthetic properties on each dictionary:
- name - the name of the tag
- attrs - a dictionary of attributes on the element
- content - a string containing the content body of the tag.
So parsing the following XML would produce the following object:
<page>
<title id="12345">Lorem ipsum</title>
<revision>
<contributor>
<user id="2345">bobtherealuser</user>
</contributor>
<text>
Lorem ipsum {R:delor}
</text>
</revision>
</page>
{
"attrs": {},
"name": "page",
"content": null,
"title": {
"attrs": {
"id": "12345"
},
"name": "title",
"content": "Lorem Ipsum"
},
"revision": {
"attrs": {},
"name": "revision",
"content": null,
"contributor": {
"attrs": {},
"name": "contributor",
"content": null,
"user": {
"attrs": {
"id": "2345"
},
"name": "user",
"content": "bobtherealuser"
}
},
"text": {
"attrs": {},
"name": "text",
"content": "Lorem ipsum {R:delor}"
}
}
}
The output object isn't beautiful, but it is predictable and it carries all of the information that we'll need, regardless of whether it is an attribute, content, or nested structures.
At this point, we could try invoking our parser with the following:
def on_page(page):
print(page["title"] if "title" in page else "No title")
with bz2.open('enwiki-latest-pages-articles-multistream.xml.bz2') as file:
load_xml(file, on_page)
Modeling Pages
Though we could pass our nested dictionaries around to consumers, this would likely become a source of bugs and maintenance issues over time if more bits of parsing are required. To help prevent those maintenance issues, we can define a few simple models that will represent the pages and use those rather than raw import objects.
class Page:
def __init__(self):
self.title = None
self.namespace = None
self.id = None
self.last_edit = None
class RedirectPage(Page):
def __init__(self):
super()
self.target = None
def __str__(self):
return f”{self.namespace}.{self.id} ({self.last_edit}): '{self.title}' -> '{self.target}'”
class ContentPage(Page):
def __init__(self):
super()
self.content = None
def __str__(self):
return f”{self.namespace}.{self.id} ({self.last_edit}): '{self.title}' -> '{self.content[0:64]}'”
With these models defined, the next task for us would be to create a mapping function that takes our external data and maps it into a controlled representation for use in our logic.
def _map_dict_to_page_model(page):
if not page['name'] == 'page':
return None
if "redirect" in page:
model = RedirectPage()
model.target = page['redirect']['attrs']['title']
else:
model = ContentPage()
model.content = page['revision']['text']['content']
model.title = page['title']['content']
model.id = int(page['id']['content'])
model.namespace = int(page['ns']['content'])
model.last_edit = datetime.fromisoformat(page['revision']['timestamp']['content'][:-1])
return model
def iterate_pages_from_export_file(file, handlers):
def on_page(page_dto):
page = _map_dict_to_page_model(page_dto)
if page is not None:
[fn(page) for fn in handlers]
load_xml(file, on_page)
With this in place, we now have a method that we can use to parse a wikipedia export into a stream of defined models representing pages. Our updated test code would look like the following.
def on_page(page):
print(page)
with bz2.open('enwiki-latest-pages-articles-multistream.xml.bz2') as file:
iterate_pages_from_export_file(file, handlers=[on_page])
Storing the data in SQLite
While this technically does get us a locally available version of the Wikipedia data, our solution is hardly going to be low latency when looking for a specific bit of information; depending on where a given article appears in the stream, it could be multiple hours to retrieve like this. This might work if we're trying to find out when the clock tower will be struck days in advance, but time travels don't also have that kind of luxury. No, we need something optimized for fast searches and fast retrieval.
For this case, a simple SQLite database should do the trick. Let's start by creating the shell of a component to handle managing our database and populating it with data.
class SQLitePageWriter:
def __init__(self, filename):
self.filename = filename
def __enter__(self):
return self
def __exit__(self, exception_type, exception_value, exception_traceback):
pass
def on_page(self, page):
pass
# Updated Invocation
with bz2.open('enwiki-latest-pages-articles-multistream.xml.bz2') as file:
with SQLitePageWriter(output_filename) as sqlite_page_writer:
iterate_pages_from_export_file(file, handlers=[on_page, sqlite_page_writer.on_page])
Setting up the schema
So the first question we should ask is how do we want to store our data. For this, I chose to make five tables.
- page - A listing of all page ids and their titles
- page_content - The actual text content of every page
- page_redirect - A listing of all redirects and the pages that they redirect to
- page_redirect_broken - A listing of all pages that redirect to non-existent pages
- page_revision - Information about the last edit. Right now this is only the timestamp
In the final project, posted on GitLab, I'll replace the __enter__ and __exit__ stubs with methods that properly create the schema and manage the connection, though I'll skip it here since it tends to be more boring to read. The focus of this class is the on_page method; whenever a page is submitted to the SQLitePageWriter, it will determine whether it is a redirect or content and will store the values it contains to the appropriate table.
def on_page(self, page):
if self.uncommited_rows == 10000:
self.uncommited_rows = 0
self.connection.commit()
self.uncommited_rows += 1
self.connection.execute('''INSERT INTO page(id, namespace, title) VALUES(?, ?, ?)''',
(page.id, page.namespace, page.title))
self.connection.execute('''INSERT INTO page_revision(page_id, last_edit) VALUES(?, ?)''',
(page.id, page.last_edit))
page_type = type(page)
if page_type is ContentPage:
self.connection.execute('''INSERT INTO page_content(page_id, content) VALUES(?, ?)''',
(page.id, page.content))
if page_type is RedirectPage:
self.connection.execute('''INSERT INTO page_redirect_temp(page_id, target_name) VALUES(?, ?)''',
(page.id, page.target))
As a balance between speed and memory, I opted to run transactions in batches of 10,000 pages. This made them sufficiently fast while still managing to fit in a few hundred megabytes of RAM.
Finishing it up
At this point, all of our pieces should be in place. All that is left is to fire it off and wait to see if it works as desired.
$ python app.py ./Downloads/enwiki-latest-pages-articles-multistream.xml.bz2 ./wikipedia.db3
Page Count: 21100561, Pages per second: Global (2568) / Momentary (5072)
Creating page_title index
Creating page_title_insensitive index
Calculating Redirect Targets
Extracting redirects
Creating Indices
Committing
Some two to three hours later, our script has ingested the entirety of Wikipedia, consuming roughly 2500 page elements every second. So, did it work?
SELECT *
FROM page
INNER JOIN page_content pc on page.id = pc.page_id
WHERE title = 'Altoona, Alabama';
350 milliseconds later I can tell you that the coal mining town of Altoona, AL was founded in 1900, incorporated in 1908, and that it has a population of under 1000 people.
I call our mission accomplished. As a potentially reluctant time traveller, I think that locality of information and access speed meet our goals. Now as long as no ne'er-do-well decides to share the results from queries like Alabama Crimson Tide football statistical leaders into the past, we should be fine. Though really, what are the chances that time travel would be abused for personal gain?